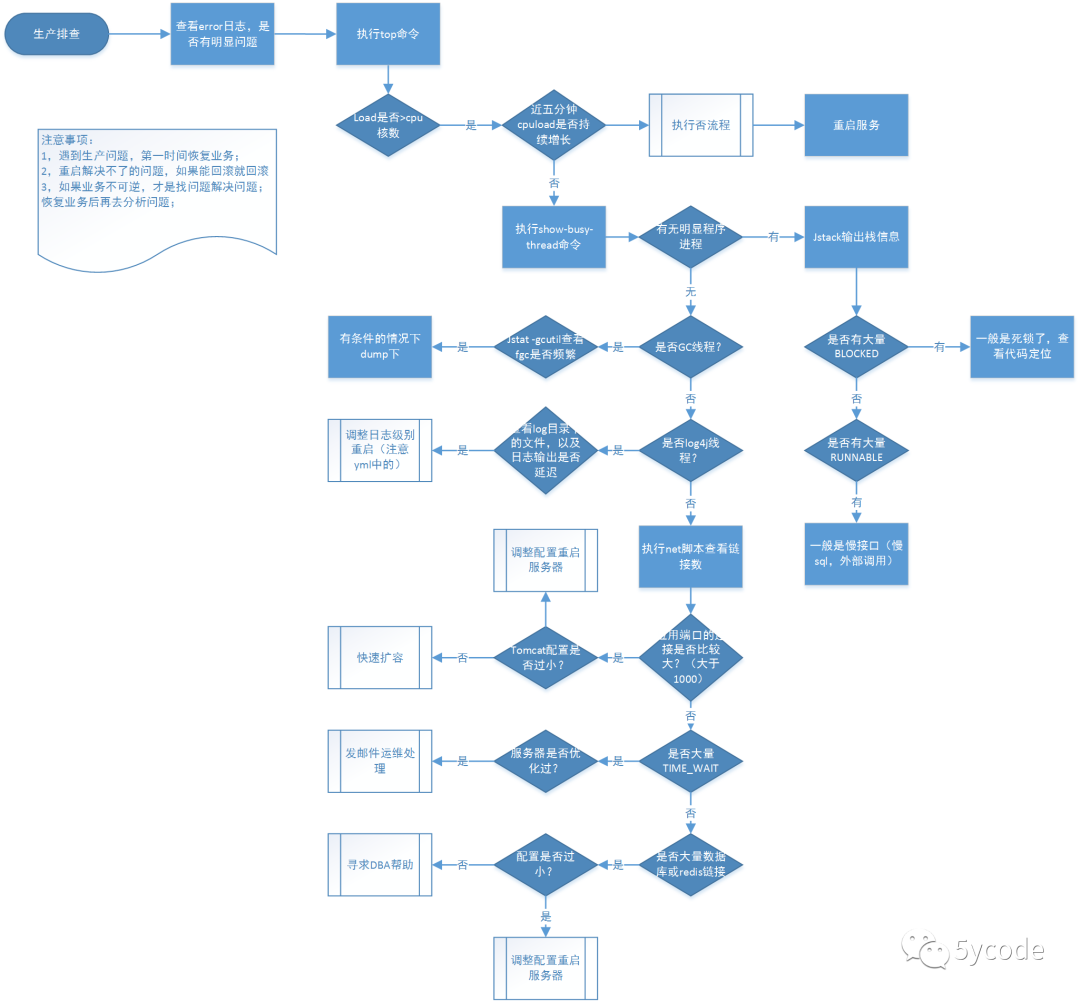
整理资料时,发现几年前的整理的问题问题排查手册,分享下。 生产问题处理的基本原则: 第一时间恢复业务(重点) 重启解决不了的问题,能回滚就回滚 如果业务不可逆,才是找问题的解决的时候(一旦到了这里,说明,大版本改动,没有做Bplan) 恢复业务后再去分析问题 执行top命令 重点查看 load averag 设 A(0.41近5分钟)B(0.32 近10分钟)C(0.32 近15分钟) 如:0.41 代表近5分钟的load值,第一个0.32 代表近10分钟的load值,第二个0.32代表近15分钟的load值; 假…

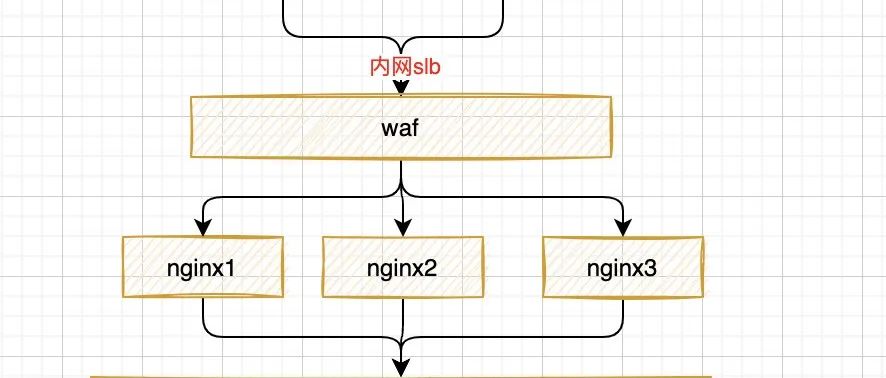
推文502 背景 前几周,运营做营销活动推文,推文后,我们我们没有收到任何的系统报警。业务反馈,用户进不去页面,有的还报502。what? 抓紧时间排查。 cpu 正常 网络链接正常(单机ng的有效链接1000,单机流量200mb) 链路请求正常(10分钟内超过2秒的接口不到1000条,大部分还都是银行卡相关的) 数据库也正常 都正常啊,怎么就502了?看下ng的超时日志,最近10分钟内,单机也就几百个,不应该怎么慢啊。 不对,突然想起来在打开后端系统的有点卡顿。 难道是网络带宽耗尽了? 马上找运维看了下公网带宽,…

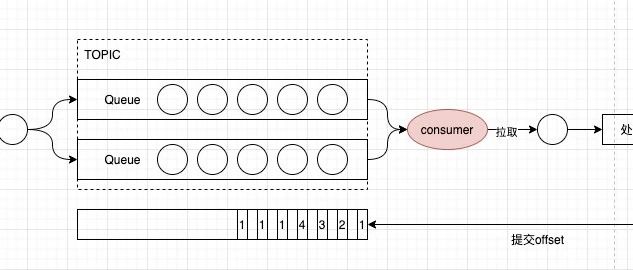
我记得在2016年,2017年的时候,我们使用2.8的集群。当时业务有个需求,要求某个接口一天调用不能超过1000次,当时开发使用一个key: biz:total 来限制。 当时出现的问题是,第二天,接口实际调用量为0,但是从redis里获取到的值还是1000。 当时直接问的阿里云技术支持,反馈这种情况有两种,一种是定期删除,没有达到删除条件,一种是cpu压力过大,不会执行删除策略。 当时也没有深究这个问题,就想了个解决方案,直接把key改为 每天一个的 key: biz20170125:total 来控量,算是解…

今天开发小伙伴给我说,哥,你帮我看下吧,系统无缘无故的宕机了。之前跑了一个多月好好的。 我问了下这台机器的配置是啥? 虚拟机:1核2G jvm配置:xms:1gxmx:1g 我就开始着手查看 监控指标怎么样? 监控系统这两天在升级,暂时看不了; 开发反馈,load在1左右,cpu高峰也就80%,我先信了。 现场有无保留(堆栈信息)? 没有OOM的输出 gc日志有没有? 有,gc看着都正常 jvm的errorFile呢? 没有配置。 好吧…
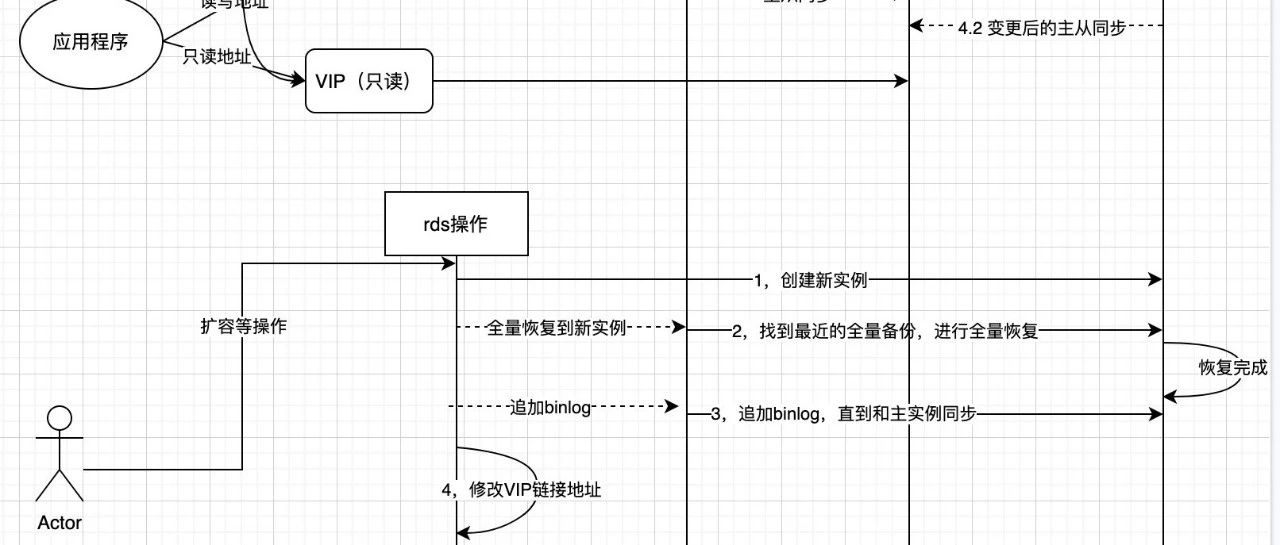
问题回顾 4月2日 开发发现专有云的用户rds实例链接数报警,并于中午发起了数据库配置变更申请; 4月8日14:00 某云在场运维巡检,发现该实例有中断的任务,尝试补偿执行失败; 4月8日14:23 某云在场运维直接手动操作跳过一些步骤,将中断任务继续执行; 4月8日17:30,许久没消息的报警群,突然收到一堆报警,用户系统提示:com.mysql.jdbc.exceptions.jdbc4.CommunicationsException,其他系统提示调用用户系统Read timed out,后续又报Connect…
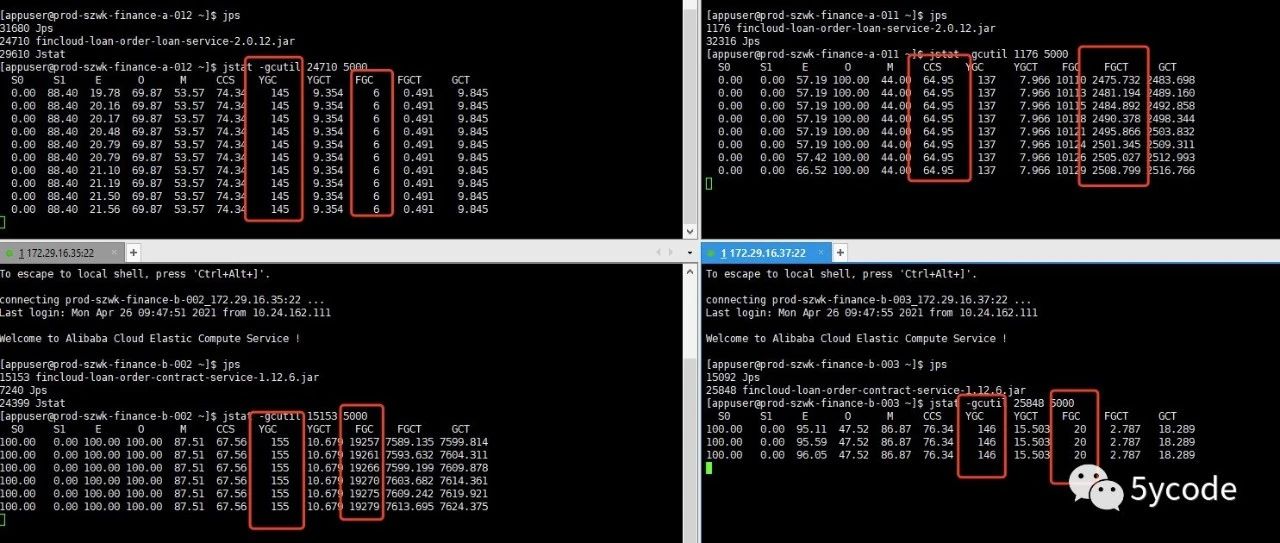
业务系统从公有云在迁移到专有云后,有几台服务器一直有问题,直接导致迁移进度无进展。通过 jstat -gcutil pid 5000 查看,发现应用程序的老年代已满,fullgc一直在增长,反而ygc很小。 猜测: 对象生成没有经过年轻代,直接进了老年代,程序里有大对象; 年轻代里没有连续的空间,导致无法创建数组直接进入老年代; 然后 jmap -heap pid 查看到应用的堆有2g,但是新生代只有167MB,新生代太小,不符合1:2的配置 Server compiler detected.JVM version…

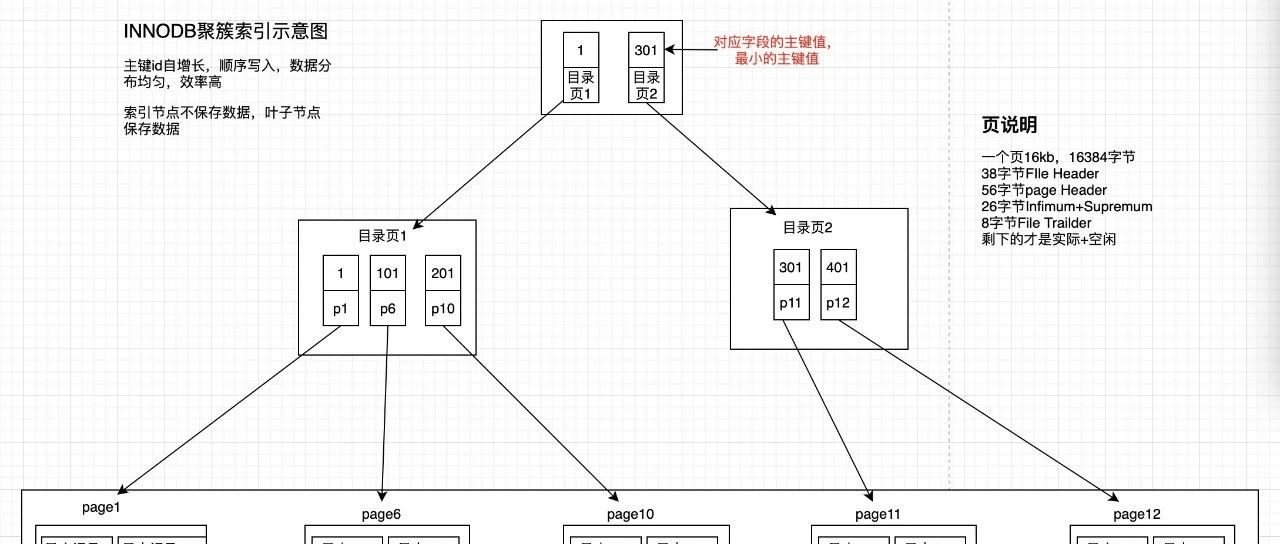
今天测试在验证的时候,测试反馈工单后台查看数据特别慢,慢到数据无法展示。那就看下呗。看了下有慢sql。 本着对生产敬畏的心态,转移到测试环境进行验证。测试数据不够,自己造呗。工单表具备以下特征: 数据字段多,索引也多; 随着数据的流转,数据一直在更新;以下数据是参考测试表结构的模拟; -- 创建表,多加了几个字段为了占用空间填充CREATE TABLE `t_loan_order` ( `app_id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT '工单ID', `cust…
