aof相关配置
aof-rewrite-incremental-fsync yes
# aof 开关,默认是关闭的,改为yes表示开启
appendonly no
# aof的文件名,默认
appendfilename "appendonly.aof"
# aof刷数据的策略,有no/everysec/aways
appendfsync everysec
no-appendfsync-on-rewrite no
# aof超出配置大小的比例,模式是100%,可以理解为阈值
auto-aof-rewrite-percentage 100
# aof 配置的文件的大小,默认64mb
auto-aof-rewrite-min-size 64mb
aof-load-truncated yes
# rewrite 进行时候,rewrite 文件分两种格式,1. 先 用 rdb 序列化,序列化结果写入aof文件,然后期间积累的差异用追加aof命令格式 ,2 整个文件都是aof的命令追加格式
aof-use-rdb-preamble yes appendfsync 一共有3种策略
- alays 主要有数据改动就把数据刷入磁盘,性能相对最差,但最安全
- everysec 每隔1秒刷一次数据,redis默认的,也是redis推荐的
- no 不主动刷,什么时候刷数据,取决于操作系统,大多数linux 30秒提交一次
aof写入:
在之前分析redis的流程的时候《redis源码阅读三-终于把主线任务执行搞明白了》里读取客户端信息的时候
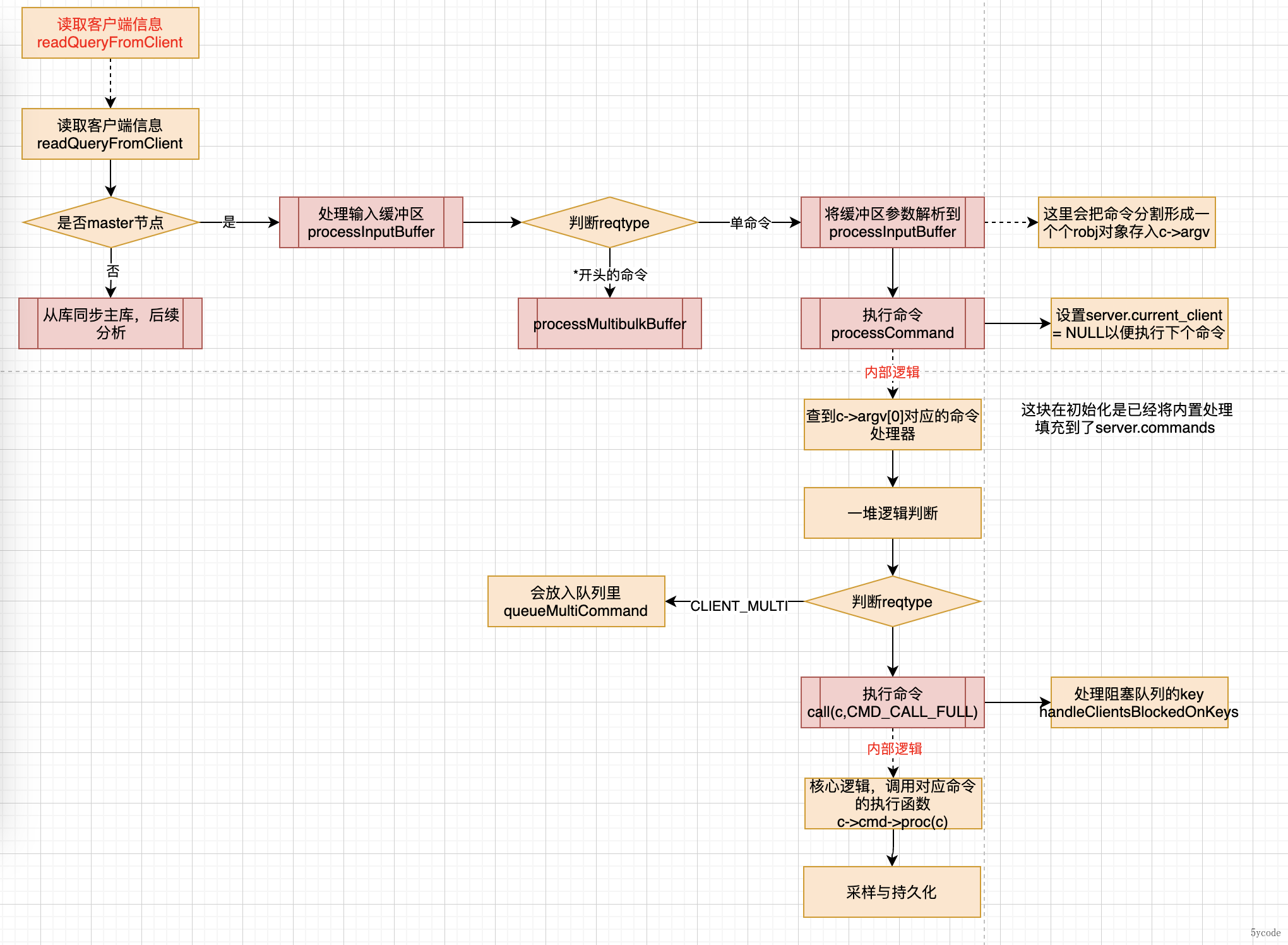
在processCommand 函数里,解析出来执行命令,放入了client中
int processCommand(client *c) {
//解析出来命令
c->cmd = c->lastcmd = lookupCommand(c->argv[0]->ptr);
//CMD_CALL_FULL 包含着CMD_CALL_SLOWLOG | CMD_CALL_STATS | CMD_CALL_PROPAGATE
//CMD_CALL_PROPAGATE 包含着CMD_CALL_PROPAGATE_AOF|CMD_CALL_PROPAGATE_REPL
call(c,CMD_CALL_FULL);
}
//命令执行
void call(client *c, int flags) {
/**
* dirty 记录修改次数
* start记录命令开始执行时间us
* duration记录命令执行花费时间
*/
long long dirty;
ustime_t start, duration;
int client_old_flags = c->flags;
struct redisCommand *real_cmd = c->cmd;
//从server.dirty中获取
dirty = server.dirty;
//命令执行,会执行对应的redisCommand
c->cmd->proc(c);
//计算执行时间
duration = ustime()-start;
//在对应的命令里执行一次,dirty+1
//这里表示本次命令有多少次修改
dirty = server.dirty-dirty;
if (flags & CMD_CALL_PROPAGATE && (c->flags & CLIENT_PREVENT_PROP) != CLIENT_PREVENT_PROP){
if (propagate_flags != PROPAGATE_NONE && !(c->cmd->flags & CMD_MODULE))
propagate(c->cmd,c->db->id,c->argv,c->argc,propagate_flags);
}
}
/**
* 传播执行的命令到aof或从节点
* @param cmd
* @param dbid
* @param argv
* @param argc
* @param flags
*/
void propagate(struct redisCommand *cmd, int dbid, robj **argv, int argc,
int flags)
{
if (server.aof_state != AOF_OFF && flags & PROPAGATE_AOF)
//aof追加(主要是生成aof内容,并追加到.aof_buf)
feedAppendOnlyFile(cmd,dbid,argv,argc);
if (flags & PROPAGATE_REPL)
//主从复制处理
replicationFeedSlaves(server.slaves,dbid,argv,argc);
}在feedAppendOnlyFile方法里主要是aof内容生成,方法就不具体列了,主要做了三件事
- 组装刚执行命令的aof内容buf,将过期时间由相对转成绝对(重点)
- 如果AOF开启的情况,将刚组装的buf放入到server.aof_buf 后
- 如果正在重写aof,将buf写到 server.aof_rewrite_buf_blocks中(在aofRewriteBufferAppend里)
/**
* aof重写的情况下调用,将buf写到一个链表里
* @param s aof信息
* @param len
*/
void aofRewriteBufferAppend(unsigned char *s, unsigned long len) {
listNode *ln = listLast(server.aof_rewrite_buf_blocks);
aofrwblock *block = ln ? ln->value : NULL;
while(len) {
//将传递过来的s写入到aof_rewrite_buf_blocks
}
//现在是主进程,如果有管道,通过管道server.aof_pipe_write_data_to_child 给子进程
if (aeGetFileEvents(server.el,server.aof_pipe_write_data_to_child) == 0) {
aeCreateFileEvent(server.el, server.aof_pipe_write_data_to_child,AE_WRITABLE, aofChildWriteDiffData, NULL);
}
/**
* 将server.aof_rewrite_buf_blocks 中的数据写入server.aof_pipe_write_data_to_child子进程的管道里
* 此处增量更新的数据,会由子进程在将虚拟空间里的数据落地后再次读取
* @param el
* @param fd
* @param privdata
* @param mask
*/
void aofChildWriteDiffData(aeEventLoop *el, int fd, void *privdata, int mask) {
while(1) {
ln = listFirst(server.aof_rewrite_buf_blocks);
block = ln ? ln->value : NULL;
if (block->used > 0) {
//通过管道把block->buf里的数据写给子进程
nwritten = write(server.aof_pipe_write_data_to_child, block->buf,block->used);
if (nwritten <= 0) return;
memmove(block->buf,block->buf+nwritten,block->used-nwritten);
block->used -= nwritten;
block->free += nwritten;
}
if (block->used == 0) listDelNode(server.aof_rewrite_buf_blocks,ln);
}
} 这里有几个变量
- server.aof_buf aof缓冲区,用于存放每次执行命令后的aof信息
- server.aof_rewrite_buf_blocks 只要是有aof的子进程,就把新产生的命令添加上去
- server.aof_pipe_write_data_to_child aof 子进程的管道,用于将server.aof_rewrite_buf_blocks信息给子进程
在主进程执行命令后,并没有写aof文件,只是将命令拼装成了字符串,放入到了aof缓冲区server.aof_buf 中,如果有aof的子进程,将aof信息放入到server.aof_rewrite_buf_blocks 然后通过管道将该信息给到子进程。
那aof是什么时候写入到文件里呢?,别急,看下图
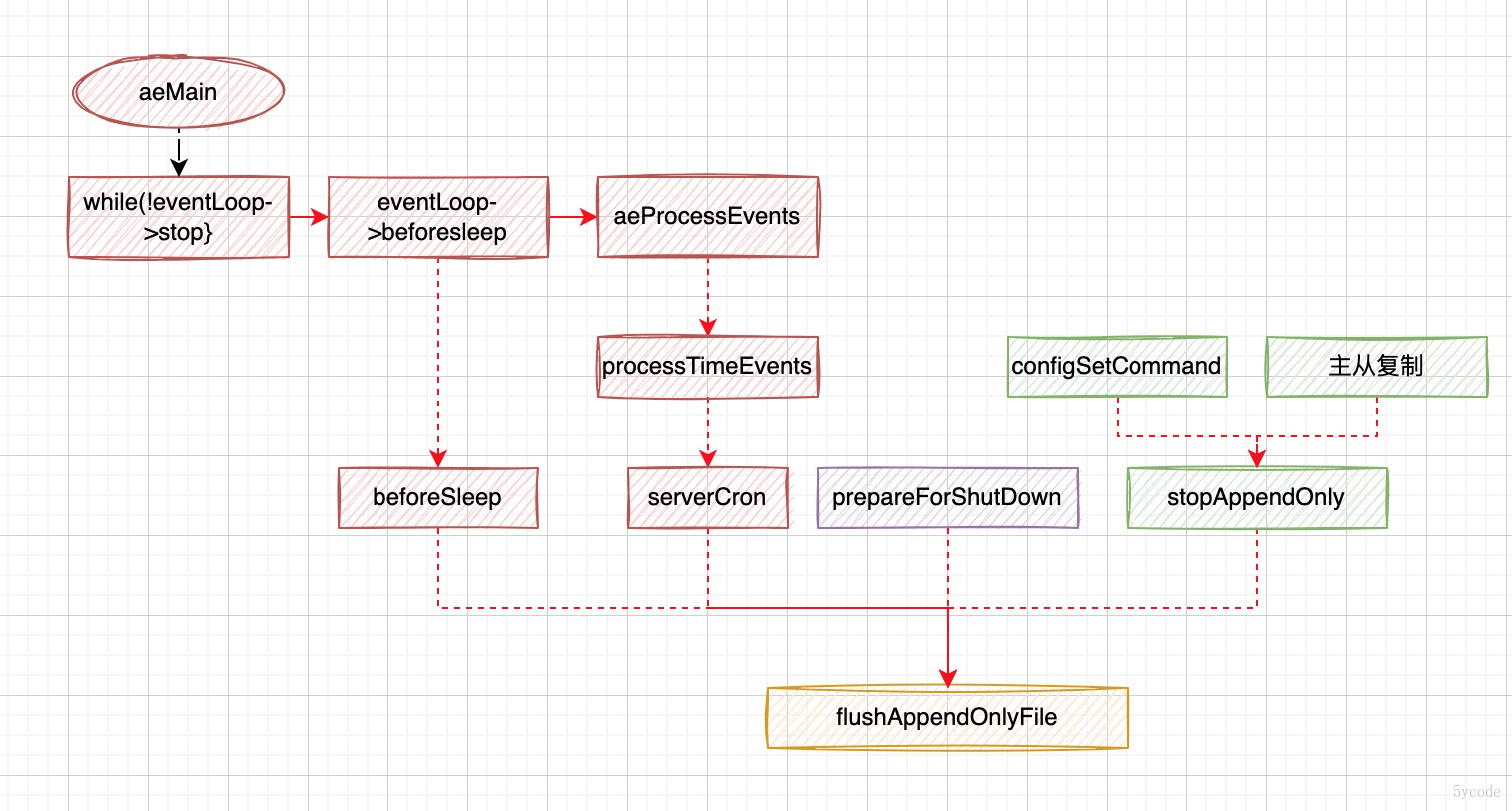
aof有几个场景的写入:
- 在主流程的循环体里
- 在循环执行前的beforesleep里
- 在serverCron里
- 准备停止之前调用一次
- 通过configSetCommand设置
- 主从复制
最终都是调用的flushAppendOnlyFile
//在beforeSleep里,没有任何的逻辑判断,直接调用
void beforeSleep(struct aeEventLoop *eventLoop) {
//将aof缓冲区写入磁盘
flushAppendOnlyFile(0);
}
//在serverCron中
int serverCron(struct aeEventLoop *eventLoop, long long id, void *clientData) {
//设置了刷入延期开始时间,直接调用
if (server.aof_flush_postponed_start) flushAppendOnlyFile(0);
//每秒再判断一次,如果上一次执行异常,再刷入一次
run_with_period(1000) {
if (server.aof_last_write_status == C_ERR)
flushAppendOnlyFile(0);
}
}
/**
* 刷入文件
* @param force 1 强制,0不强制
*/
void flushAppendOnlyFile(int force) {
//每秒刷入的时候,判断一下aof的fsync是否在bio线程里执行了,是sync_in_progress 为true
if (server.aof_fsync == AOF_FSYNC_EVERYSEC)
sync_in_progress = aofFsyncInProgress();
//每秒并且非强制刷入
if (server.aof_fsync == AOF_FSYNC_EVERYSEC && !force) {
if (sync_in_progress) {
//刷入延期开始时间为0,表示没有任何的执行
if (server.aof_flush_postponed_start == 0) {
//先将刷入延期开始时间置为当前时间
server.aof_flush_postponed_start = server.unixtime;
return;
//以后再来,只要当前时间-开始时间<2直接返回(所以对redis的aof来说,并不是每秒执行,而是至少2秒以上,如果阻塞了,时间更久)
} else if (server.unixtime - server.aof_flush_postponed_start < 2) {
return;
}
server.aof_delayed_fsync++;
}
}
//这里用了卫语句的方式,将不能触发的在前面拦截
//写入到aof文件里
nwritten = aofWrite(server.aof_fd,server.aof_buf,sdslen(server.aof_buf));
//写完aof后,将刷入延期开始时间置为0
server.aof_flush_postponed_start = 0;
//省略异常的处理
//记录aof当前的大小
server.aof_current_size += nwritten;
/**
* aof的可用buf比较小了,就清空buf
*/
if ((sdslen(server.aof_buf)+sdsavail(server.aof_buf)) < 4000) {
sdsclear(server.aof_buf);
} else {
sdsfree(server.aof_buf);
server.aof_buf = sdsempty();
}
}
//aof写入方式的枚举
configEnum aof_fsync_enum[] = {
{"everysec", AOF_FSYNC_EVERYSEC},
{"always", AOF_FSYNC_ALWAYS},
{"no", AOF_FSYNC_NO},
{NULL, 0}
}; - aof的写入是在beforeSleep 里,在serverCron 主要是处理延期写入或者处理写入异常
- aof通过server.aof_flush_postponed_start来延期写入,第一次将此值赋值为当前时间,写完以后置为0
- aof通过write写入文件(获取的是文件fd对应的偏移指针,顺序写)
aof重写
在上一篇《redis源码阅读-持久化之RDB》中
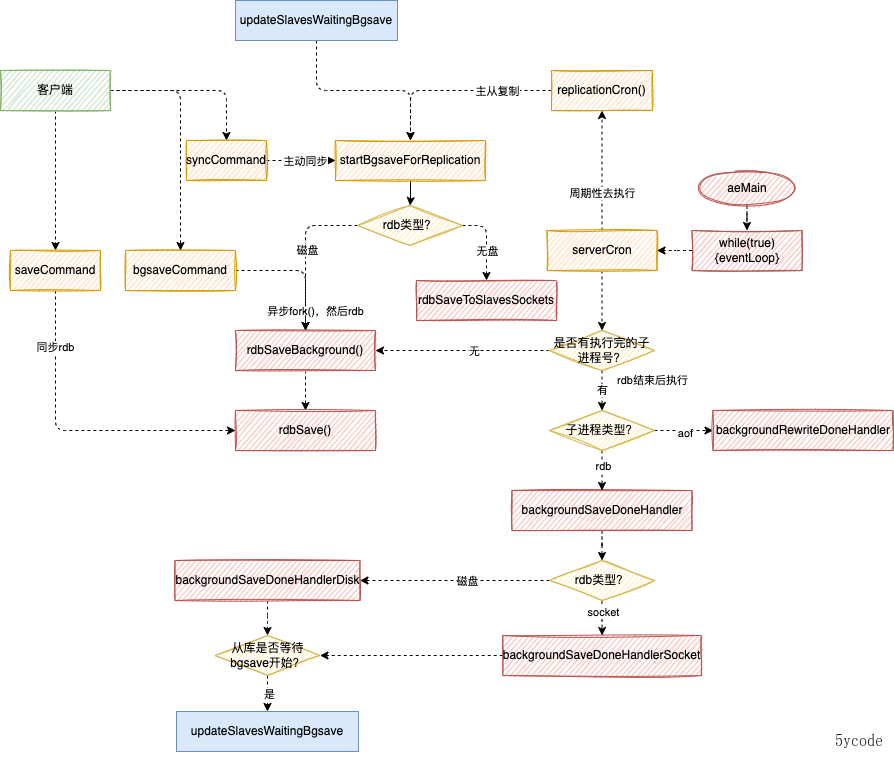
serverCron在执行的时候,有一个backgroundRewriteDoneHandler方法,当时就有疑问,这个重写是干啥的?
然后搜索了下,发现了这个函数rewriteAppendOnlyFileBackground
我们看下这个函数的触发的时机
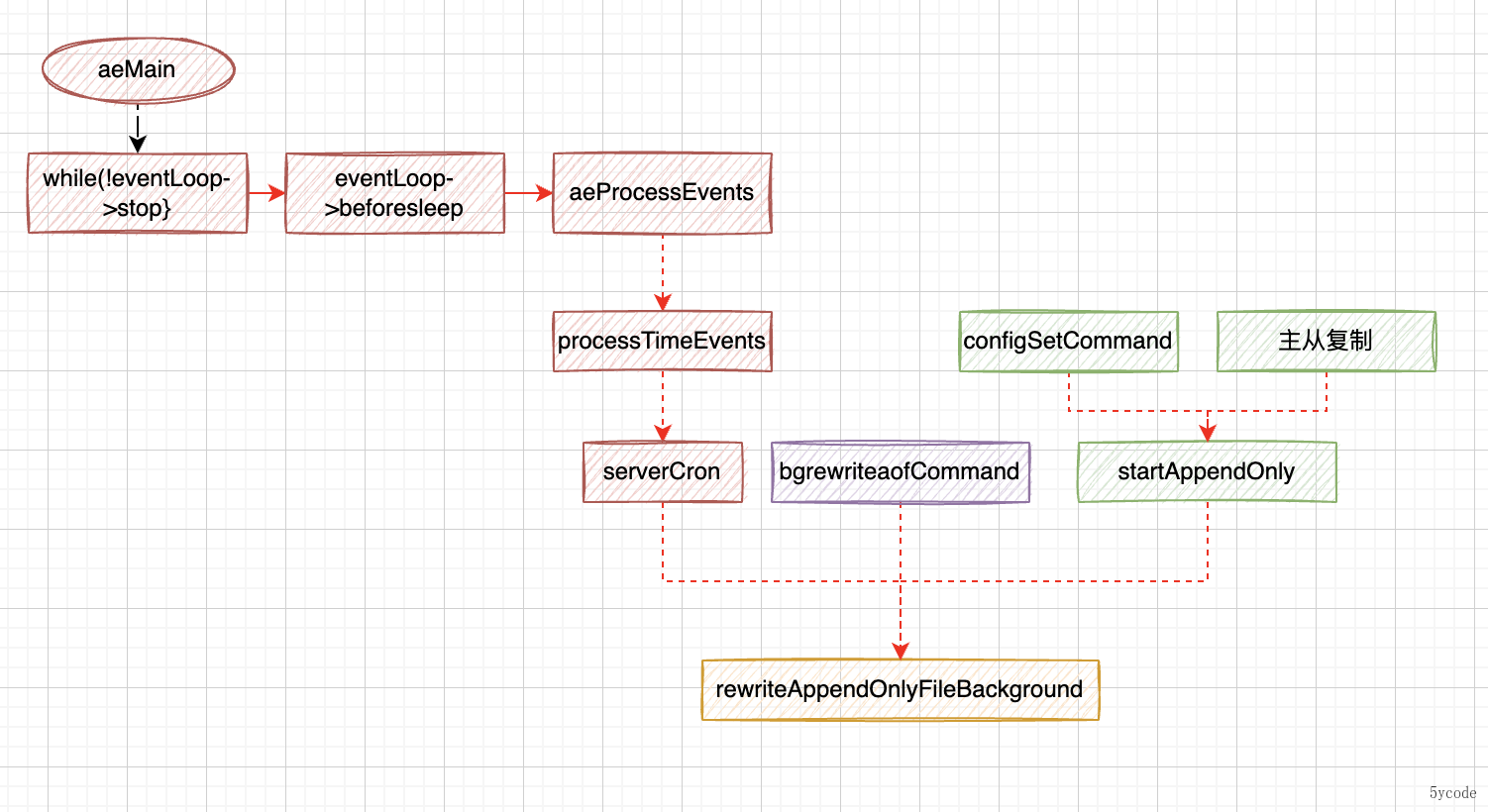
先说下触发时机:
- 在周期性循环里进行
- 通过命令调用执行aof重写
- 一个是bgrewriteaofCommand
- 一个是configSetCommand
- 主从复制时触发
在serverCron里有两次调用
int serverCron(struct aeEventLoop *eventLoop, long long id, void *clientData) {
/**调用①,这次调用是之前有rdb进程的时候,设置为了aof重写等待任务(本该执行的逻辑之前因为rdb没有执行,所以直接触发)*/
if (server.rdb_child_pid == -1 && server.aof_child_pid == -1 && server.aof_rewrite_scheduled){
rewriteAppendOnlyFileBackground();
}
if (server.rdb_child_pid != -1 || server.aof_child_pid != -1 ||ldbPendingChildren()){
}else {
/** 调用②
* 在没有rdb和aof子进程的时候,
* 先判断rdb是否达到了执行条件
* save 900 1 配置的判断
* 再判断aof是否达到了执行条件
* 1,先判断aof是否打开
* 2,如果有rdb或aof子进程了也不再执行(互斥)
* 3,有触发阈值,
* 4,aof当前的文件的大小大于设置的最小大小
*/
if (server.aof_state == AOF_ON && server.rdb_child_pid == -1 && server.aof_child_pid == -1 && server.aof_rewrite_perc &&
server.aof_current_size > server.aof_rewrite_min_size)
{
/**
* aof_rewrite_base_size 启动默认为0,第一次达到min_size以后设置为1,这时候触发
* 等待aof重写完以后,会把aof_rewrite_base_size设置为重写后的大小,这个值一致随着aof文件大小自增
*/
long long base = server.aof_rewrite_base_size ?server.aof_rewrite_base_size : 1;
/**
* 这个公式也很有意思,aof的重写会随着文件的变大而逐步变大,而不是64mb
*/
long long growth = (server.aof_current_size*100/base) - 100;
if (growth >= server.aof_rewrite_perc) {
//触发aof重写
rewriteAppendOnlyFileBackground();
}
}
}
}- ① 位置标注的调用是为了延迟补偿
- ②位置标注的每次在没有rdb和aof子进程的情况下都会进来
- redis通过server.aof_rewrite_scheduled来控制aof的延迟执行
/**
* 后台的方式重写aof,通过fork进程处理
*
* @return
*/
int rewriteAppendOnlyFileBackground(void) {
pid_t childpid;
long long start;
//双重校验,只要有aof或rdb的子进程就不再执行,
if (server.aof_child_pid != -1 || server.rdb_child_pid != -1) return C_ERR;
//创建6个管道,分别用来数据传输,父子进程之间的ack响应
if (aofCreatePipes() != C_OK) return C_ERR;
//创建执行aof完以后回写的管道
openChildInfoPipe();
start = ustime();
//fork子进程进行重写
if ((childpid = fork()) == 0) {
char tmpfile[256];
/* Child */
//关闭自己不需要关注的
closeClildUnusedResourceAfterFork();
//设置进程名称
redisSetProcTitle("redis-aof-rewrite");
//格式化重写aof的文件名
snprintf(tmpfile,256,"temp-rewriteaof-bg-%d.aof", (int) getpid());
//重写aof文件
if (rewriteAppendOnlyFile(tmpfile) == C_OK) {
size_t private_dirty = zmalloc_get_private_dirty(-1);
server.child_info_data.cow_size = private_dirty;
sendChildInfo(CHILD_INFO_TYPE_AOF);
exitFromChild(0);
} else {
exitFromChild(1);
}
} else {
/* Parent */
server.stat_fork_time = ustime()-start;
server.stat_fork_rate = (double) zmalloc_used_memory() * 1000000 / server.stat_fork_time / (1024*1024*1024); /* GB per second. */
latencyAddSampleIfNeeded("fork",server.stat_fork_time/1000);
if (childpid == -1) {
closeChildInfoPipe();
aofClosePipes();
return C_ERR;
}
//已经开始处理了,就把等待任务表示写回0
server.aof_rewrite_scheduled = 0;
//标记aof重写开始的时间
server.aof_rewrite_time_start = time(NULL);
//标记aof的的子进程
server.aof_child_pid = childpid;
//禁用hash resize
updateDictResizePolicy();
server.aof_selected_db = -1;
replicationScriptCacheFlush();
return C_OK;
}
return C_OK; /* unreached */
}
/**
* 创建aof管道
* @return
*/
int aofCreatePipes(void) {
int fds[6] = {-1, -1, -1, -1, -1, -1};
int j;
if (pipe(fds) == -1) goto error; /* parent -> children data. */
if (pipe(fds+2) == -1) goto error; /* children -> parent ack. */
if (pipe(fds+4) == -1) goto error; /* parent -> children ack. */
/* 设置数据管道为非阻塞 */
if (anetNonBlock(NULL,fds[0]) != ANET_OK) goto error;
if (anetNonBlock(NULL,fds[1]) != ANET_OK) goto error;
/**
* 注册时间处理,监听 server.aof_pipe_read_ack_from_child 传递过来的ack信息,如果有就 server.aof_stop_sending_diff = 1;
* 同时删除server.aof_pipe_read_ack_from_child的事件处理器
*/
if (aeCreateFileEvent(server.el, fds[2], AE_READABLE, aofChildPipeReadable, NULL) == AE_ERR) goto error;
//父进程往子进程写数据的管道
server.aof_pipe_write_data_to_child = fds[1];
//子进程从父进程读数据的管道
server.aof_pipe_read_data_from_parent = fds[0];
//子进程发送ack给父进程的管道
server.aof_pipe_write_ack_to_parent = fds[3];
//父进程读子进程发送的ack信息的管道
server.aof_pipe_read_ack_from_child = fds[2];
//父进程发送ack信息给子进程的管道
server.aof_pipe_write_ack_to_child = fds[5];
//子进程读取父进程发送的ack信息的管道
server.aof_pipe_read_ack_from_parent = fds[4];
server.aof_stop_sending_diff = 0;
return C_OK;
error:
for (j = 0; j < 6; j++) if(fds[j] != -1) close(fds[j]);
return C_ERR;
}rof重写
/**
* 同步重写aof
* @param filename
* @return
*/
int rewriteAppendOnlyFile(char *filename) {
rio aof;
FILE *fp;
char tmpfile[256];
char byte;
//又创建了一个临时文件
snprintf(tmpfile,256,"temp-rewriteaof-%d.aof", (int) getpid());
fp = fopen(tmpfile,"w");
if (!fp) {
return C_ERR;
}
server.aof_child_diff = sdsempty();
//初始化一个文件io对象
rioInitWithFile(&aof,fp);
if (server.aof_rewrite_incremental_fsync)
rioSetAutoSync(&aof,REDIS_AUTOSYNC_BYTES);
/**
* aof_use_rdb_preamble = yes 表示开启了混合模式,先将rdb信息刷入aof文件
* rdb是比较节省空间
*/
if (server.aof_use_rdb_preamble) {
int error;
if (rdbSaveRio(&aof,&error,RDB_SAVE_AOF_PREAMBLE,NULL) == C_ERR) {
errno = error;
goto werr;
}
} else {
//直接以redis的协议从所有db的全局hash表中读取数据写入aof文件
if (rewriteAppendOnlyFileRio(&aof) == C_ERR) goto werr;
}
//清空缓冲区
if (fflush(fp) == EOF) goto werr;
//刷入磁盘,正常都是在操作系统的页缓存里,fsync可以刷入磁盘
if (fsync(fileno(fp)) == -1) goto werr;
int nodata = 0;
mstime_t start = mstime();
/**
* 在1秒内,每次等待1毫秒,从管道里获取数据
*/
while(mstime()-start < 1000 && nodata < 20) {
//等待管道数据,没有数据,下一次轮训
if (aeWait(server.aof_pipe_read_data_from_parent, AE_READABLE, 1) <= 0)
{
nodata++;
continue;
}
nodata = 0; /* Start counting from zero, we stop on N *contiguous*
timeouts. */
//从父进程读取追加的数据
aofReadDiffFromParent();
}
/* Ask the master to stop sending diffs. */
//向父进程发送ack信息!,让父进程停止追加
if (write(server.aof_pipe_write_ack_to_parent,"!",1) != 1) goto werr;
//读取master的ack信息
if (anetNonBlock(NULL,server.aof_pipe_read_ack_from_parent) != ANET_OK)
goto werr;
//同步读取父进程的ack消息,5秒超时
if (syncRead(server.aof_pipe_read_ack_from_parent,&byte,1,5000) != 1 ||
byte != '!') goto werr;
/* Read the final diff if any. */
//再次读一下,补救ack期间传过来的数据
aofReadDiffFromParent();
//将aof开始执行之后,追加的数据写入到aof文件中
if (rioWrite(&aof,server.aof_child_diff,sdslen(server.aof_child_diff)) == 0)
goto werr;
//清空缓冲区
if (fflush(fp) == EOF) goto werr;
//刷入磁盘,正常都是在操作系统的页缓存里,fsync可以刷入磁盘
if (fsync(fileno(fp)) == -1) goto werr;
if (fclose(fp) == EOF) goto werr;
//将rof的临时文件改名为temp-rewriteaof-bg-%d.aof
if (rename(tmpfile,filename) == -1) {
unlink(tmpfile);
return C_ERR;
}
return C_OK;
werr:
fclose(fp);
unlink(tmpfile);
return C_ERR;
}通过以上的代码我们可以看到:
- aof的重写过程和bgsave方式的rdb差不多的过程差不多
- aof 重写有两种模式,一种是先写rdb,再追加aof(混合模式),一种是一路aof格式
- aof在将虚拟内存空间里的数据写完以后,会通过wait轮训从管道server.aof_pipe_read_data_from_parent里获取增量更新的数据,增量更新在第一小节的时候,有个aofChildWriteDiffData处理器(通过FileEvent机制写入)
- 然后aof 子父进程发送ack确认消息
- 最后再次通过rioWrite 将ack期间追加的数据补救回来
- 最后将rof的临时文件重命名为temp-rewriteaof-bg-进程id.aof
aof后续处理
其实到这里,aof是写到文件里了,但是并没有再改到配置的文件上?
别急,我们上一篇,或者本篇aof小结那张图。
在serverCron有一个分支处理backgroundSaveDoneHandler 和backgroundRewriteDoneHandler。上一篇,我们讲过了backgroundSaveDoneHandler,另一个方法backgroundRewriteDoneHandler没有讲,翻看代码看下
/**
* 后台aof重写后的处理
* @param exitcode 获取子进程的结束代码,exitcode=0 表示rdb成功,1表示失败
* @param bysignal 子进程信号中断代码,如果有值,表示被信号中断
*/
void backgroundRewriteDoneHandler(int exitcode, int bysignal) {
if (!bysignal && exitcode == 0) {
//格式化子进程的文件名
snprintf(tmpfile,256,"temp-rewriteaof-bg-%d.aof",
(int)server.aof_child_pid);
//以写模式打开
newfd = open(tmpfile,O_WRONLY|O_APPEND);
//将写入缓冲区aof_rewrite_buf_blocks的数据追加到aof文件数上
if (aofRewriteBufferWrite(newfd) == -1) {
}
//将临时文件改为真正的aof文件
if (rename(tmpfile,server.aof_filename) == -1) {}
if (server.aof_fd == -1) {
close(newfd);
} else {
//把新的aof文件的fd赋值过去,redis可以实时写入,这些操作都是线性的
oldfd = server.aof_fd;
server.aof_fd = newfd;
//根据类型是否直接刷盘
if (server.aof_fsync == AOF_FSYNC_ALWAYS)
redis_fsync(newfd);
else if (server.aof_fsync == AOF_FSYNC_EVERYSEC)
aof_background_fsync(newfd);
server.aof_selected_db = -1; /* Make sure SELECT is re-issued */
aofUpdateCurrentSize();
//重置aof的base_size
server.aof_rewrite_base_size = server.aof_current_size;
//aof的偏移指针
server.aof_fsync_offset = server.aof_current_size;
/* Clear regular AOF buffer since its contents was just written to
* the new AOF from the background rewrite buffer. */
sdsfree(server.aof_buf);
server.aof_buf = sdsempty();
}
//修改aof最近重写的状态
server.aof_lastbgrewrite_status = C_OK;
} else if (!bysignal && exitcode != 0) {
server.aof_lastbgrewrite_status = C_ERR;
}
}在最后
- 将临时文件改成了真正配置的的aof文件
- 然后又将缓冲区aof_rewrite_buf_blocks里的数据写入到了aof文件里。
redis为什么要进行aof重写呢?
- aof记录的是所有的修改操作,随着运行越来越大;
- redis作为一个缓存数据库,很多的数据是有有效期的,可能30秒后之前的键值就无效;
- 这些失效的数据,对于aof后续的恢复来说是大部分都是执行无效的数据,会导致效能过低;
- 磁盘的的占用也是一个问题,其实rdb也是这个理;
为什么aof和rdb要后台子进程运行?
-
子进程通过页映射表来读取主进程的物理数据,使用子进程,一是防止阻塞主进程,二是省去了数据的拷贝;
-
对于redis来说,对外提供高性能的服务是核心,aof和rdb是辅助性的维护手段;
-
简单来说非核心业务不要影响核心业务;
redis系列文章
redis源码阅读四-我把redis6里的io多线程执行流程梳理明白了
redis源码阅读五-为什么大量过期key会阻塞redis?
本文是Redis源码剖析系列博文,有想深入学习Redis的同学,欢迎star和关注;
Redis中文注解版:https://github.com/yxkong/redis/tree/5.0
如果觉得本文对你有用,欢迎一键三连;
同时可以关注微信公众号5ycode获取第一时间的更新哦;


文章评论