redo 日志
什么是redo日志?是为了在系统因崩溃而重启时恢复崩溃前的状态而产生的概念,mysql在运行过程中修改数据时由innodb引擎产生的(某个表空间第n号页面中偏移量为m处的值由x更新为y)记录日志,用于保证持久性;
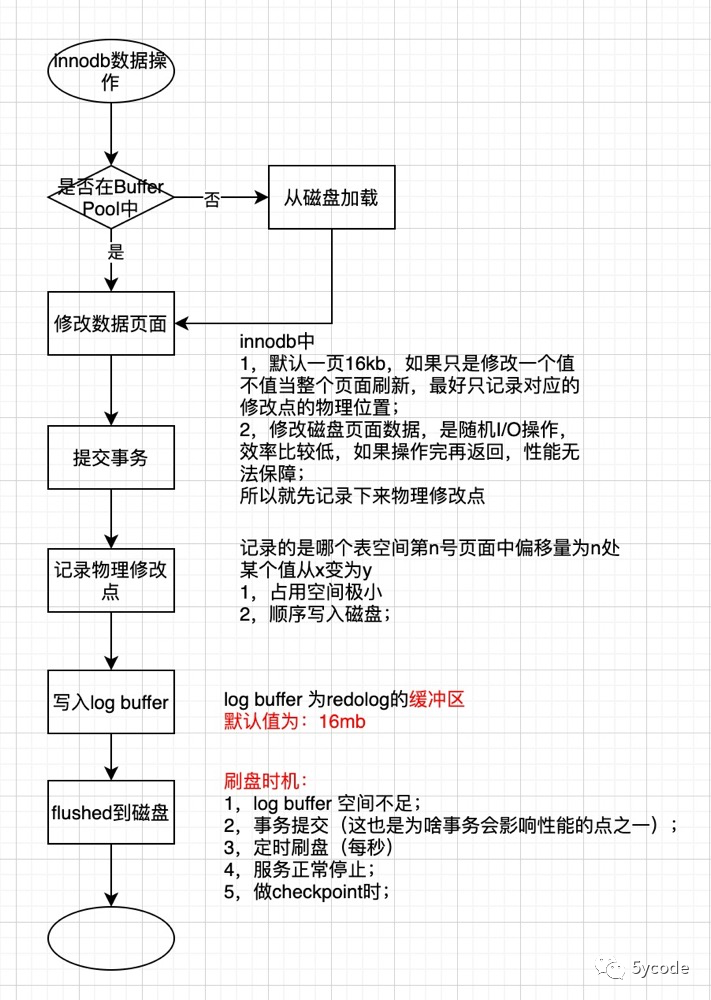
redo log从 log buffer 刷入磁盘的时机:
-
log buffer 空间不足;
-
事务提交 (这也是为啥事务会影响性能的点之一);
-
定时刷盘(每秒),通过flush链表
-
服务正常停止;
-
做checkpoint时;
innodb_flush_log_at_trx_commit 参数可以配置以什么样的机制刷入磁盘
-
0 表示由后台线程来处理;
-
1 表示同步刷盘(默认值);
-
2 表示写到操作系统缓冲区,只要操作系统不挂就没事,操作系统挂了,事务就无法保证
概念
-
MTR (Mini-Transaction)代表对底层页面的一次原子访问,这个过程会产生redo log;
-
checkpoint 表示增加checkpoint_lsn的操作的操作过程;
-
脏页:修改过的数据页
-
flush 链表:在MTR执行过程中会将修改过的页面加入到 flush 链表,采用的是头插法
数据格式:
type: redo日志的类型space ID:表空间idpage number:数据页面号data:具体内容
数据存储: redo log放在512字节的页中,也称为block;
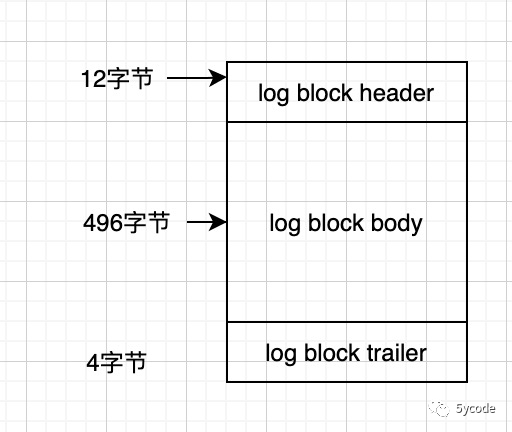
header中:存储该block的元数据:包含页号、使用了多少,已经checkpoint的序号,以及最近一次修改后对应的lsn值(每个页面中都维护了这个值,在恢复脏页时,如果这个值大于checkpoint_lsh,就不恢复)
body: 真正记录redo log的内容
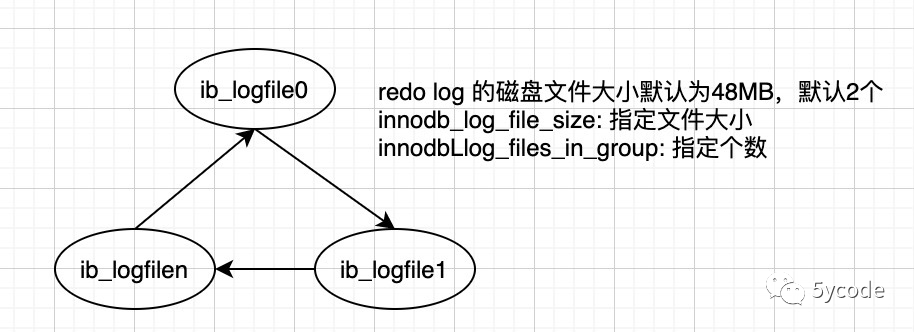
Buffer pool 和磁盘的logfile都是循环使用的,只要checkpoint了,小于checkpoint_lsn的空间都是可以覆盖写的。
redo log中的全局变量
-
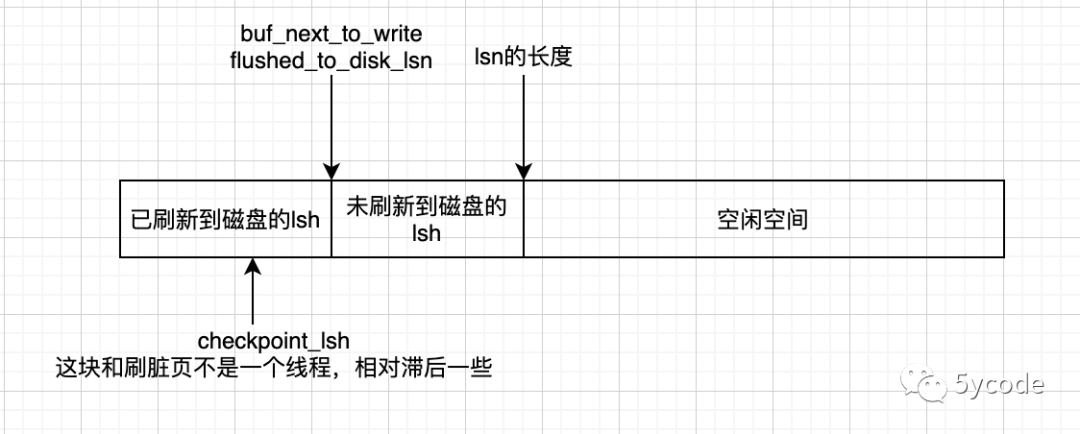
lsn:(log sequence number) 记录当前总共已经写入的redo日志量(包含 log block header 和log block trailer空间),从8704开始;
-
buf_next_to_write 标记当前log_buffer中已经刷新到磁盘的日志量;
-
flushed_to_disk_lsn: 表示刷新到磁盘中的redo日志量
-
checkpoint_lsn 用来表示当前系统中可以被覆盖的redo日志重量是多少,chekcpoint_lsn 对应的空间都可以被覆盖;
SHOW ENGINE INNODB STATUS \G;Log sequence number 表示 lsnlog flushed up to 表示:flushed_to_disk_lsnLast checkpoint at 表示 checkpoint_lsn
checkpoint 过程
-
计算可以被覆盖的redo日志对应的lsn(也就是flushed_to_risk_lsn)
-
将checkpoint_lsn对应的偏移量修改到对应的flushed_to_risk_lsn(在第一步就已经计算出了偏移量,如果过程中有增加,就不一致了)
**如何恢复?**
redolog中对应的lsn大于checkpoint_lsn的需要处理,大于checkpoint_lsn的可能刷了也可能没刷。起点:首先我们要确认lsn起点。通过redo日志文件组第一个文件的管理信息中,有两个block都存储了checkpoint_lsh的信息,哪个大就选哪个作为起始点。终点:最后的lsn位置,存满的block都是512字节,没有存满的小于512,由于是顺序写,说明这个就是终点。
不管是mysql还是ES都有checkpoint机制,当服务进程挂掉后时,从redo log或者translog上恢复数据,基本原理都差不多。
kafka没有类似的机制,kafka通过ack机制+最小同步副本集来保证持久性


文章评论