
什么是零拷贝?
零拷贝描述的是cpu不参与执行从一个存储区域到另一个存储区域的数据拷贝任务;避免让CPU做大量的数据拷贝任务,将cpu解脱出来专注于别的事,降低cpu在数据拷贝中的使用率。
零拷贝的目的
-
尽可能少的利用cpu来完成操作;
-
尽可能减少数据的读写过程;
利用零拷贝的组件
-
kafka
-
netty
-
rocketMq
-
nginx
-
基本上有文件和网络交互的为了效率都会用到
基本概念
-
DMA:直接内存访问(Direct Memory Access)DMA允许外设设备和内存存储器之间直接进行IO数据传输,其过程不需要CPU的参与
-
缓冲区:是所有IO的基础,IO的作用就是把数据写进或读取出缓冲区
-
read请求,内核空间缓冲区有直接copy,无则向磁盘或网络请求,通过DMA写入内核缓冲区,然后再copy
-
write请求,将用户空间的数据copy到内核缓存区,然后通过DMA把内核缓冲区写入磁盘或网卡;
-
虚拟内存:
-
一个以上的虚拟地址可以指向同一个物理内存地址,mmp利用这点
-
虚拟内存空间可大于实际可用的物理地址
-
内核空间:linux自身使用的空间,主要提供进程调度、内存分配、连接硬件资源等;
-
用户空间:提供给应用程序的空间
-
不具备访问内核空间资源的权限;
-
需要通过内核空间才能访问到内核资源;
-
使用内核资源,需要从用户到内核,再从内核到用户,cpu最少需要切换两次;
传统拷贝和零拷贝的区别
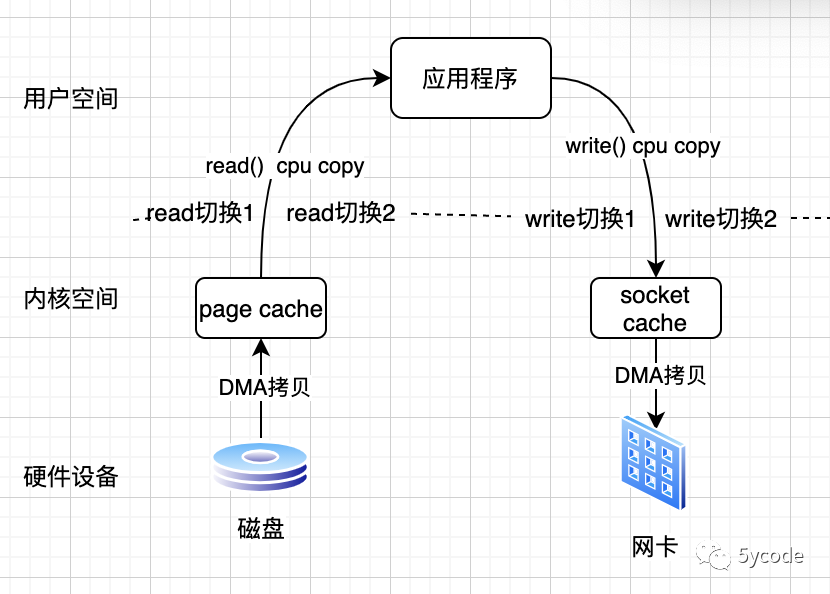
传统拷贝(基于DMA机制的copy,如果不基于DMA,则还需要两次cpu的参与)
-
应用程序发出read命令,导致由用户空间切换到内核空间;
-
通过DMA copy数据数据到page cache;
-
将数据从page cache copy到用户空间,导致由内核空间切换到用户空间;
-
应用程序发出write命令,将用户空间数据写入到socket cache中,导致由用户空间切换到内核空间;
-
写完后,返回写入状态,导致由内核空间切换到用户空间;
-
在此,总共进行了4次用户态与内核态的上下文切换,2次DMA拷贝,2次CPU数据拷贝;
零拷贝,不需要再将数据拉回应用程序
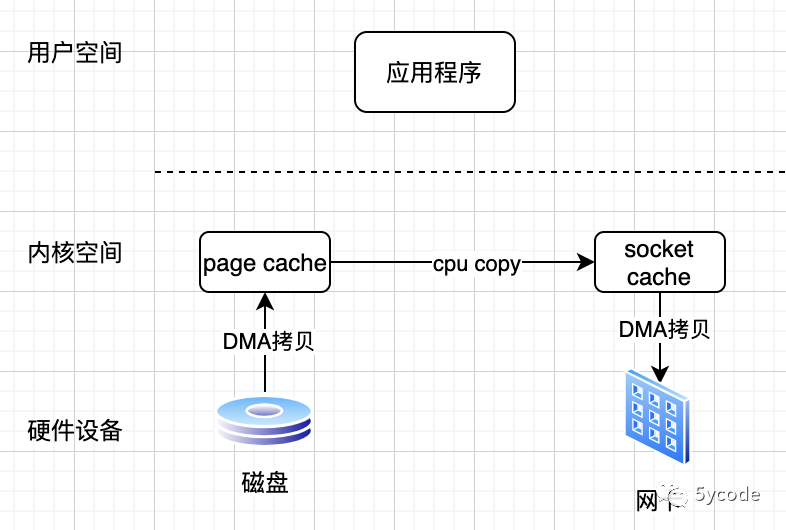
不同的零拷贝机制处理机制不太一样
零拷贝的实现机制
零拷贝的实现基于操作系统,下面所说的都是在linux中的实现。
mmap 实现
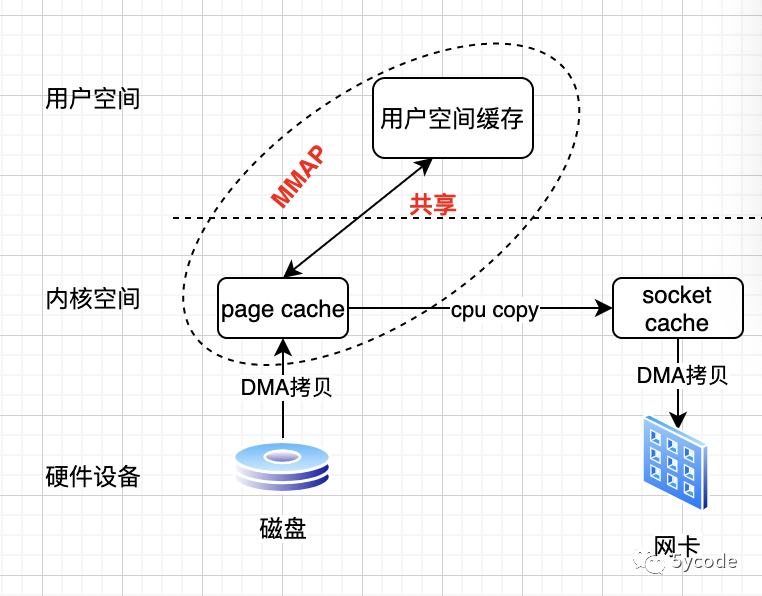
mmap 是利用虚拟内存映射的机制,代替了传统的read操作,减少了数据从内核空间到用户空间的过程;由于mmap可能是多个虚拟内存和物理内存的共享,导致一致性和原子性很难保证,别人删除了,你就无法操作;
#include <sys/mman.h>
void *mmap(void *start, size_t length, int prot, int flags, int fd, off_t offset)
-
发起mmap调用,导致由用户空间切换到内核空间;
-
mmap 系统调用返回后,导致由内核空间切换到用户空间;
-
发起write命令调用,cpu 将page cache 数据copy到socket cache中,导致由用户空间切换到内核空间;
-
wirte 调用返回,导致由内核空间切换到用户空间
-
在此,总共进行了4次用户态到内核态的上下文切换,2次DMA拷贝,1次cpu数据拷贝;
sendfile 实现
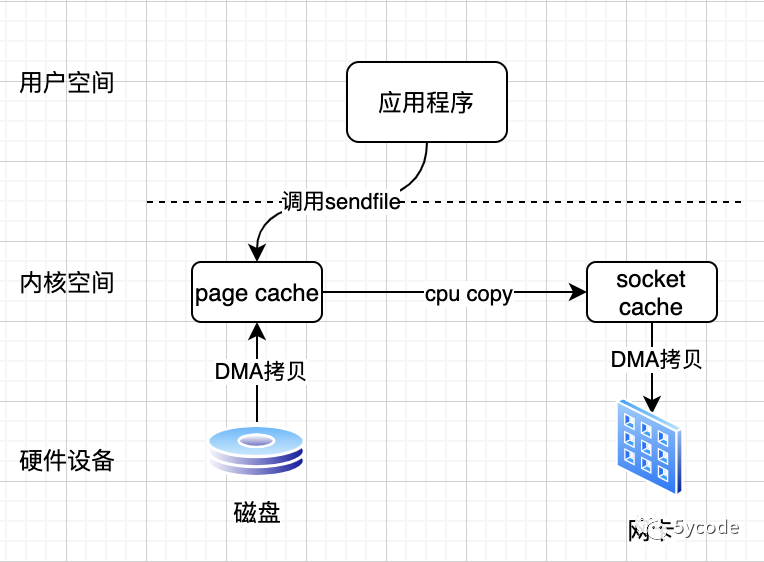
linux2.1 内核以后提供了sendfile实现了零拷贝
#include<sys/sendfile.h>
ssize_t sendfile(int out_fd, int in_fd, off_t *offset, size_t count);
参数说明:
-
out_fd:数据接收方文件句柄;
-
in_fd:数据提供方文件句柄;
-
offset:如果 offset 不为 NULL,表示从哪里开始发送数据的偏移量;
-
count:表示需要发送多少字节的数据;
-
发起sendfile时,导致由用户空间切换到内核空间;
-
直接通过DMA拷贝到page cache,再从page cache 到 socket cache进行 cpu copy;
-
sendfile 调用返回,导致由内核空间切换到用户空间;
-
DMA异步将内核socket cache中的数据传递到网卡;
-
在此,总共进行了2次用户态到内核态的上下文切换,2次DMA拷贝,1次CPU拷贝;
到linux2.4版本,操作系统提供scatter和gather的SG-DMA方式,直接从内核空间缓冲区中将数据读取到网卡,无需将内核空间缓冲区的数据再复制一份到socket缓冲区
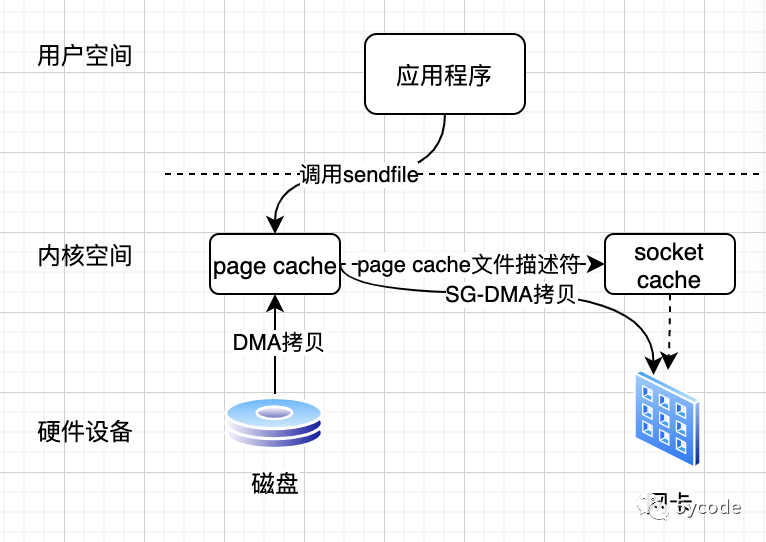
-
发起sendfile时,导致由用户空间切换到内核空间;
-
直接通过DMA拷贝到page cache;
-
将page cache 中的描述符信息复制到socket缓冲区,
-
page cache 对应的内存地址;
-
page cache 的偏移量
-
sendfile返回,导致由内核空间切换到用户空间
-
SG-DMA根据描述符直接从page cache中将数据写入到网卡
-
在此,总共进行了2次上下文切换,2次DMA拷贝;
splice 实现
linux在2.6.17版本引入splice系统调用。sendfile只适用于将数据从文件拷贝到套接字上,使用场景固定。
#define _GNU_SOURCE /* See feature_test_macros(7) */
#include <fcntl.h>
ssize_t splice(int fd_in, loff_t *off_in, int fd_out, loff_t *off_out, size_t len, unsigned int flags);
splice调用在两个文件描述符之间移动数据,而不需要数据在内核空间和用户空间来回拷贝。它从fd_in拷贝len长度的数据到fd_out,但是有一方必须是管道设备,这也是目前splice的一些局限性。flags参数有以下几种取值:
-
SPLICE_F_MOVE :尝试去移动数据而不是拷贝数据。这仅仅是对内核的一个小提示:如果内核不能从pipe移动数据或者pipe的缓存不是一个整页面,仍然需要拷贝数据。Linux最初的实现有些问题,所以从2.6.21开始这个选项不起作用,后面的Linux版本应该会实现。
-
SPLICE_F_NONBLOCK :splice 操作不会被阻塞。然而,如果文件描述符没有被设置为不可被阻塞方式的 I/O ,那么调用 splice 有可能仍然被阻塞。
-
SPLICE_F_MORE:后面的splice调用会有更多的数据。
-
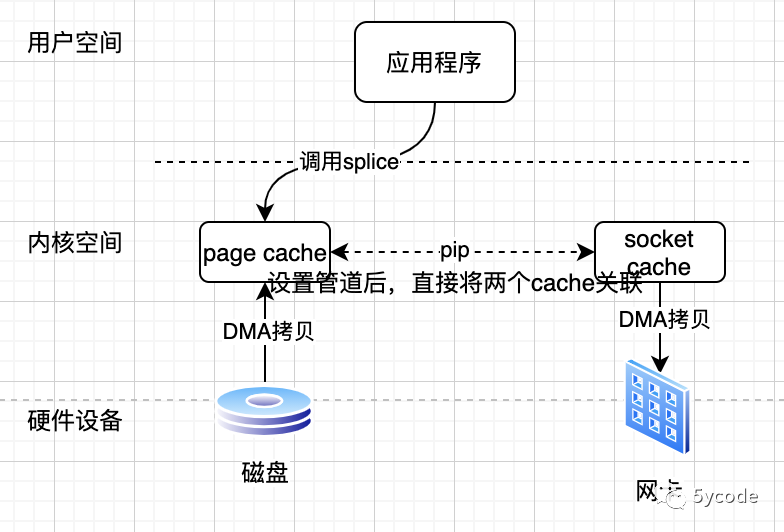
-
发起splice时,导致由用户空间切换到内核空间;
-
直接通过DMA拷贝到page cache;
-
设置管道将page cache 和socket cache进行关联
-
splice返回,导致由内核空间切换到用户空间
-
DMA通过socket cache管道直接从page cache中将数据写入到网卡
-
在此,总共进行了2次上下文切换,2次DMA拷贝;
linux中零拷贝的对比
| 拷贝方式 | 系统调用 | cpu copy | DMA copy | 上下文切换 |
|---|---|---|---|---|
| 标准 | read/write | 2 | 2 | 4 |
| mmap | mmap/write | 1 | 2 | 4 |
| sendfile | sendfile | 1 | 2 | 2 |
| sendfile sg-dma | sendfile | 0 | 2 | 2 |
| splice | splice | 0 | 2 | 2 |
零拷贝带来的好处
-
cpu参与度降低,可以释放出来做更多的事;
-
数据copy次数减少,系统IO降低;
-
用户应用程序可以通过底层命令直接访问硬件存储;
-
数据尽可能由硬件完成;
后续有空再来一篇java中的零拷贝


文章评论